SnowFlake Introduction and architecture
Posted on by Sumit KumarSnowflake is the first analytical data warehouse build on the cloud. It provides a data warehouse as Software-as-a-Service (SaaS).
It started with AWS but now available across three of the market’s largest public cloud providers.

Snowflake is faster, easier to use and far more flexible than tradition warehouse.
In this blog, we will discuss the architecture of snowflake.
Snowflake architecture is a combination of both shared disk architecture and Shared nothing architecture.
Shared disk architecture:-
Shared disk architecture uses multiple nodes to access the data shared on a single storage system.

Shared nothing architecture:-
Shared nothing architecture store a portion of the data in each node in each cluster in a data warehouse.

Snowflake combines the benefits of both architectures to get an innovative new design that can take full advantage of the cloud.
Similar to Shared disk architecture, it uses central data repository to persist the data that will be accessible from all compute nodes in the data warehouse and similar to Shared nothing architecture it process query using Massive multiple processing (MMP) cluster where a portion of the entire dataset will be stored in each node locally.
So it takes advantage of Shared disk architecture to store the data and for query processing, it takes advantage of Shared nothing architecture approach.
Snowflake multi-cluster shared architecture consist of three key layers:-
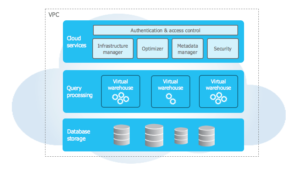
1)Database Storage layer:-
Snowflake store all data in databases. The database is a logical grouping of an object , consisting primarily of tables and views organized into one or more schema. Similar to other databases, we can store any structure relational data in snowflake table using standard SQL database. Apart from Structure data snowflake VARIANT datatype allow us to store semi-structured data(eg:-JSON, AVRO, etc). Regardless of any data type, we use SQL to perform any data related task. Snowflake uses highly secure cloud storage to maintain all the stored data. As data loaded into table snowflake convert this table into optimized, columnar, compressed and encrypted using AES-256 strong encryption.
2)Query Processing layer:– Also known as compute layer where the query has been executed using resource that is provided by the cloud provider. Unlike traditional architecture Snowflake allow us to create multiple independent compute cluster called virtual warehouse. Each Virtual warehouse can access same data storage layer without contention and performance degradation because of this if any update or insert happen in any records it will be immediately available at all virtual warehouse.
3) Cloud services:- This layer coordinate and manages the entire system. It helps to authenticate user, manages session, secure data and perform query compilation and optimization. Services layer also manages virtual warehouse and co-ordinate data stored, update and access and ensuring that once the transaction has been completed all virtual warehouse see the new version of data with no impact on the availability and performance.
The key component of Services:-
Metadata store:- This having many features like zero-copy cloning, Time Travel, and data sharing.
We can connect to snowflake using JDBC/ODBC along with that we can use the command-line client (snowSql) and also a WebUI.
Hope this will help you to understand the basic of the snowflake. For more details explanation please visit Snowflake documentation
Next blog we will learn how to run a query on snowflake via python connector.


Leave a Reply